

I really like this quote:
“You can think of the Large Language Model (LLM) as an over-enthusiastic new employee who refuses to stay informed with current events but will always answer every question with absolute confidence.”
So when to use RAG and when to use fine-tuning?
Imagine that you are running a news desk back in the 90’s. Tempo is hectic. To validate news leads and to write an analysis of the current situation, you have two resources at your disposal. A young promising researcher, sent to the front line to do field research, and a grey-haired veteran newspaper guru who has seen every conflict since the Korean war.
The field researcher on the front line interviews people and brings back original documents for further analysis. The guru with extensive experience from multiple conflicts is able to provide in depth analyses of emerging situations, for example, the conundrums the leaders are facing, and the implications of each decision option.
They bring two different qualities.
The researcher can provide up-to-date information, references to the sources of information (albeit that the editor has to first tell him to where to go). The field researcher is timely, but chronically lacks the ability to see the wood for the trees.
The guru on the other hand, can provide deep analysis from emerging situations and write his column in language that the target audience finds appealing. However, like an old parrot, the guru is prone to repeat passé statements.
He likes to rant about “the danger of hard rock music” even though other reporters roll their eyes and repeatedly remind him that the music industry has long moved on.
The researcher is an AI model using RAG, while the old guru is an analogy for fine-tuning.
Use fine-tuning when
- You want the model to answer in an expected way, in a specific domain.
- Your corpus can rely heavily on memorization. A good example here would be questions/answers on documents.
- Specialized domain language, terminology and nuances are used in the interaction with the model.
- The model should adhere to certain guidelines, for example, reply in a specific language.
- You want the model to produce consistent output formatting, for example, provide answers in JSON or table format.
Use RAG when
- Dynamic, up-to-date information is required. For example, an AI model can be connected to a traffic congestion database to provide up-to-date information of the traffic situation.
- When factual accuracy is critical. RAG helps a model provide accurate quotes with source references.
- When information is pulled from a wide array of sources.
- For massive LLM’s, RAG is often the preferred choice due to the compute required by fine- tuning. As an example, fine-tuning an Open AI model through their web interface can take 6 hours.
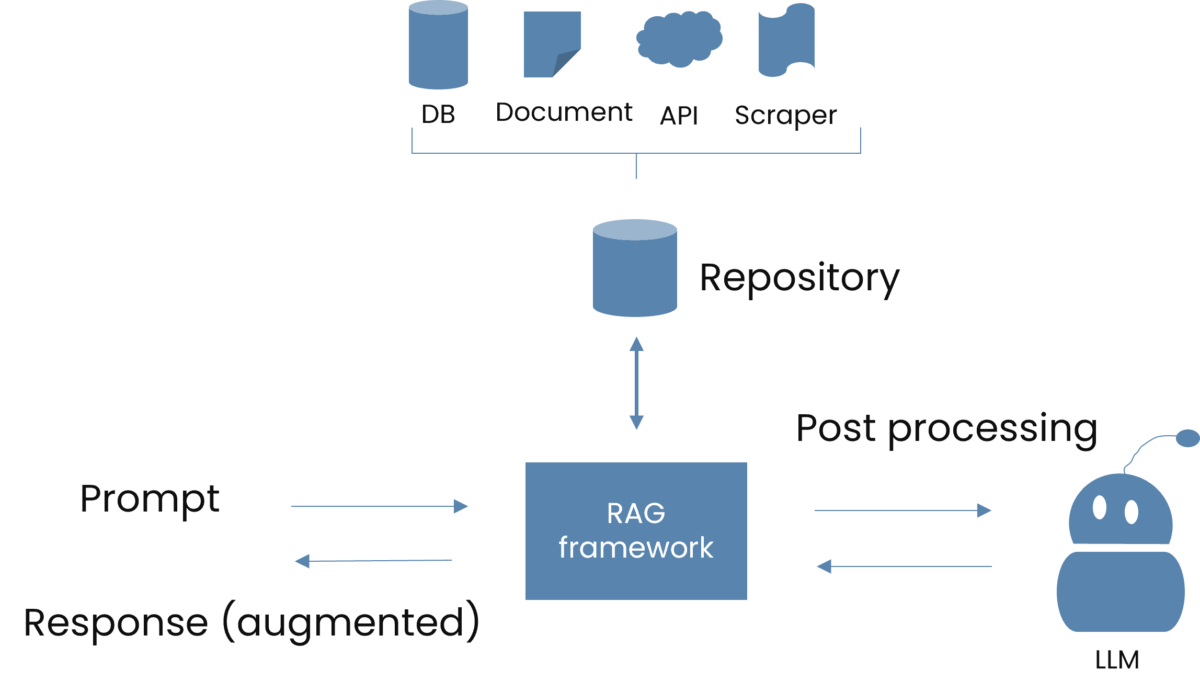
How RAG Works
Retrieval-Augmented Generation, or RAG, allows the LLM to present accurate information with source attribution.
If the term is a bit of a mouthful for you, you are not alone. Patrick Lewis, the lead author of the paper that coined the term, said this about the somewhat awkward name:
“We always planned to have a nicer sounding name, but when it came time to write the paper, no one had a better idea.”
How does RAG work?
The user sends in a question (often called “prompt”, or “query”). This is processed by the RAG framework. Think of the RAG framework as a librarian who directs your request to the relevant area of the library.
You: “I’d like to learn about the latest development on AI.”
Librarian: “We need the IT section. Let’s take a look there.”
In the next step, your query is used to craft search terms from which document matches can be found.
Librarian: “The words ‘AI’, ‘development‘ and ‘latest” are search teams that match a recent article from the AI journal. Let’s pull out the relevant sections from that article”
Note that the whole article is not forwarded to the next step post processing, only the relevant sections of it are. This is due to a pre-processing step where the article has been indexed, or “chunked”. It’s those matching chunks that are passed forward in the process.
Librarian: “Now that we have a boatload of information, we need to summarize it somehow. I have a great editor colleague we can ask for help. Let’s head over to her. We’ll pass on the articles we found together with the instruction:
“Compile a summary of the latest developments in the domain of AI, including RAG, fine-tuning, open source models, compute developments, parallel processing in GPU’s including wild untethered statements from AI company leaders who desire to attract huge investments.”
Now the final step kicks in. The LLM we use compiles the information, producing an augmented response. The “augmented” component is the direct reference to the original sources, which helps to preserve quotes and data.
How fine-tuning works
Fine-tuning is about adopting a pre-trained model to a particular task using a small, specific dataset.
The nice thing with fine-tuning is that the whole model (its weights) does not need to be re-trained from scratch, rather, the weights are updated based on the customized dataset.
Fine-tuning can be used in both open source (for example Llama) and proprietary models (Open AI). In the latter case, fine-tuning is done through an API or using the model provider’s website (in other words, LLM can be fine-tuned even though the actual model is hidden, it’s wrapped by the API).
The steps in fine tuning:
- Select a pre-trained model (LLM).
- Curate a custom dataset (aim for 100 to a few thousand data samples).
- Set the training parameters (hyper parameters).
- Fine-tune model with the custom dataset.
- Evaluate the model.
- Deploy it.
Often, the curated dataset is provided in the form (“question”, “answer”) mirroring the terminology and tone fit for a specific domain. For example: “answer like a BBC reporter using the Queen’s English”
Q: “What is on the agenda today, might I ask?”
A: “My goodness, it’s afternoon tea!”
Fine-tuning is programmatically pretty straight forward. However, it can be compute intense for large models. The compute power can be significantly reduced through tricks like LoRa and QLoRA, which use clever matrix mathematics and reduction of integer sizes (32->8, 32->4) when updating model weights. The use of these techniques makes it possible to make use of the fine-tuned model in a smaller device such as a smartphone.
RAG Frameworks
Frameworks and tools for RAG is a fast-evolving space. Here’s a shortlist of frameworks that should be on your radar.
| Framework | About | Key features |
| Langchain | Modular, well-established framework for RAG solutions (open source) | Customizable for a variety of use cases due to modular design Integrates with vector data bases such as Pinecone, FAISS, Chroma Loaders for PDF, text, web scraping, and SQL databases Generate dynamic prompts using template structures |
| LangGraph | An evolvement from basic RAG. As agent orchestration framework, LangGraph allows you to build customizable LLM Agents (open source) | Create complex, yet controllable workflows using Tools, Memory and LLM’s Built in persistence mechanism – “shared state” between nodes in workflow. Conversation history support, using Memory Allows for human-in-the-loop |
| LlamaIndex | Focuses on efficient indexing and retrieval from big datasets (open source) | Workflows can be constructed using GUI Run retrieval testing configuring the data loader Run Health checks in the GUI Loaders for files (TXT, PDF, DOC, CSV), databases (SQL/NoSQL), and web scraping Integrates with local LLM’s through Ollama Uses ElasticSearch and Infinity for data storage |
| RAGFlow | GUI supported RAG workflows Ideal for fast prototyping of RAG workflows (open source) | Workflows can be constructed using GUI Run retrieval testing configuring the data loader Run Health checks in the GUI Loaders for files (TXT, PDF, DOC, CSV), databases (SQL/NoSQL), and web scraping Integrates with local LLM’s through Ollama Uses ElasticSearch and Infinity for data storage |
| NeMo-Guardrails | NeMo is an open source framework for implementing guardrails (“rails”) into an LLM app Guardrails are specific methods of controlling the output of a large language model. For example as not discussing politics, responding in a particular way to specific user requests or following a predefined dialog path | Safety and security Design rails to guide talks and specify you LLM’s dialog behavior Direct your LLM to follow a specific dialog path |
Summary
Both RAG and fine-tuning are techniques used to improve the accuracy and usability of a model in a specific domain. If up-to-date information and accuracy is required, RAG is the preferred choice.
If specific language, nuances and guidelines are to be followed, fine-tuning is the preferred choice.


