Back in the days when the web emerged, all companies scrambled to have their own website (never mind what to use it for). When cloud computing came, companies raced to migrate their technology platform to cloud based.
It makes sense to quickly learn what a new shiny toy is about and what it can do. But wiser still is to understand what to use it for, before throwing billions of $$ at it.
This article is about how to craft an AI strategy that does just that.
On the challenges with Generative AI
Before we can head on to setting up a strategy, we need to have a basic understanding of what technology can and cannot do. However, extracting this information from the glut of articles is surprisingly difficult you’d find anything from doomsday to AGI (being just around the corner) everywhere you look.
The first balanced thing to do is to take the hype statements from AI company leaders with skepticism. Ask yourself if they have things in the AI space they want to sell? That helps to unmask overly positive hype statements to get to a more sober reality.
How LLMs work
It’s important to point out that there are different categories of AI solutions. They are not all the same.
A first level categorization is to group AI solutions into Generative AI, and Diskriminative (able to make distinctions with accuracy) AI.
Generative means they have the capability to create things. For example, an AI image model can produce a new image of an Astronaut riding a horse on the moon, an LLM can produce a poem that is yet to be written. That’s the generative part of the AI. Large Language Models belong to the Generative AI family.
How do LLMs work? In essence, they try to predict the next word.
| Example: | The AI tries to predict the next word. To do that, it chooses among a list of candidates: |
| A cat sat on a __ | Word : Likelihood of fit: ————————- Flat : 5 % Hat : 30% Mat : 60% … : 5% |
Andrej Karphathy dubbed this as LLMs’ “stochastic simulations of people”, a telling description that reveals the nature of LLMs. They have a stochastic (“random”) element inside them, this is what makes them Generative.
LLMs get trained on large bodies of texts written by humans, think of it as a tape recording with a huge memory with the capability to play back. It is impressive, but it is not the same as “thinking”. It is essentially “mirroring” what other clever people would say in similar situations.
Over belief in Generative AI
Generative AI is like a coin with two flipsides. On one side, it is allowed to be creative, on the flip side, it causes the AI to make up things that don’t exist – it “hallucinates”, and it can be very persuasive about it being right. It actually has no mechanism to evaluate its level of confidence. That makes it very different from humans.
Unfortunately, this means that Generative AI solutions like LLMs aren’t very precise. Sure, we can put scaffolding in place (human-in-the-loop, finetuning, RAG etc) to avoid the craziest responses, but we can’t stop LLMs from hallucinating. It’s a built-in trait due to its stochastic nature and the method of training. It’s what makes it creative in the first place.
This makes Generative AI solutions a bad fit for domains where the cost of error is big, where precision and robustness is required. When considering the choice of AI solutions, as a rule of thumb, ask yourself: is a success rate of > 95% required? If so, go for alternative solutions – there are plenty!
My point is not that LLMs are bad, it’s that we carry an overuse bias in what it can do. The fact that it impresses in coding challenges and conversations drives us to believe that it can do just about anything, which is simply not true. Would you trust an LLM to drive your car? Of course not.
The key is to know that the domain where Generative AIs shine is in the creative space.
“Ok, I get it.” you say. That’s great. But knowing about this is only half of the problem. Here’s why:
The LLM ecosystem temptress
The big providers in the LLM space are working hard to set up ecosystems around their services, simplifying putting LLMs to use. This makes it very hard to avoid using LLMs, even if you wanted to. They are increasingly embedded in both APIs and in AI toolchains.
The “ease of use” is a double-edged sword, it makes it a tempting proposition to turn the development of a new app into an LLM problem, even when it’s not.
Setting up a useful AI strategy
Given that the AI space is fast moving, how do I set up a strategy that holds over time?
Elements of a simple yet robust AI strategy:
- Understand your use case.
- Organize your data.
- Use custom data for context fit.
- Automate the most time-consuming use cases
- Make employees supervisors and improvement agents for operational AI solutions.
- Start simple, evolve gradually to more advanced ML algorithms (evolve to advanced only when they improve results).
- Involve ethics from the start. A working solution is not a tech problem, it’s a trust issue. Legal frameworks are not going to be helpful, the bar is too low, it’s a new playbook. So it’s better is to engage ethics from the start.
Understand your use case
The MIT report “The Gen AI Divide: State of the AI in Business 2025” concluded that only 5% of enterprise AI solutions make it to production.
The main reason AI implementations fail is because of unclear business use cases.
If you mix a poor understanding of the use case (what creates value) with explorations of an emerging technology, this can easily throw you into a product development process similar to Brownian motion.
To avoid this, start with a deep understanding of the value case, then bring in technology where it creates a difference. Avoid doing it the other way around—rolling out new technology in the hope that it may solve a problem.
Use custom data for context fit
Does your business save data? If so, make good use of it. Use that data to differentiate your AI solutions. This is a simple way of creating a hard-to-copy advantage.
A good example is finetuning an AI solution so they respond using language and terminology accustomed to the specialized domain.
Another example is building in real-time integrations to databases and services, so your AI solution can be integrated with real-time information (for example, “what is the traffic situation right now on the logistics route?”).
A very interesting field of development to enable this is Synthetic data. Synthetic data allows you to create larger training data sets from small, well-crafted samples of real data. I expect this field to grow rapidly in the upcoming years.
To sum it up:
AI model + custom data = context fit and improved usability
Organize your data
Given that we have understood that we want to use custom data as a differentiator, we have now stumbled upon the foundational element of good AI solutions – organized data.
This work is often overlooked because of its unglamorous nature, but rest assured, all companies with impressive AI solutions wouldn’t be there today without years of hard work mining and organizing data.
The problem is rarely a lack of data, but rather, its quality and unavailability (scattered around in isolated data islands).
To organize data for qualitative AI development, we have five problems to solve:
- Learn where we have sources of interesting data, and make it accessible through a central point so they can be used by data scientists and developers.
- Mine the data – Data needs to be cleaned, for example empty data points filtered out.
- Masking of sensitive information (for example personal identification).
- Describing the data – “what does this data represent”. This can, for example, be solved through descriptive metadata.
- Automation of the above process.
This is hard work. But this is where smart companies build their strategic advantage. While well working AI solutions may steal the spotlight, they are in essence the icing on the cake.
If data is the new oil, organizing your data is your refinery.
Automate the most time-consuming use cases
Rather than building the solution with the ambition of replacing them entirely. Build the solution so that it allows for “human-in-the-loop” from the start. From that point, you can gradually reduce the situations requiring human intervention.
This is by far a better tactic than the reverse—building the solution with the ambition to replace humans entirely only to find out it was way harder than you imagined.
A good example is self-driving cars. By 2018 they were expected to drive around the streets in just a few years’ time. In 2025 they are driving but within limited domains. Often with human supervision in the car or for a distance. They are still a decade or so away from being as flexible as humans under varying conditions.
So, start with a selection of the most time-consuming use cases, then gradually reduce the situations requiring human intervention
Make employees AI training supervisors
Did you know that Toyota actually started as a textile company? Toyota’s first product success was the automated spinning machine. The launch of these weaving machines meant that weavers could shift from weaving on one machine to operating a pool of weaving machines.
While this meant a huge leap in productivity, the less talked about advantage was that this allowed experienced weavers to shift from weaving fabrics to improving the process of weaving.

There is an opportunity to create a similar leap of productivity in knowledge work with the use of AI. Instead of a knowledge worker being the producing engine, he (or she) can shift to improving a pool of AI agents tasked with the job.
When a knowledge worker operates a pool of AI agents, he or she can advance the performance of the AI agents over time, allowing them to handle a growing set of scenarios, and complexity. There are several advantages with a strategy like this, the really neat one is that it allows for much faster feedback cycles, edging close to real-time improvement pace.
Advantages of employees as AI training supervisors:
- It allows for automation with “human-in-the-loop”.
- Employees are given a role in AI operation.
- Can be implemented using existing AI training technologies (for example: fine tuning, reinforcement learning from human feedback, transfer learning, few-shot learning).
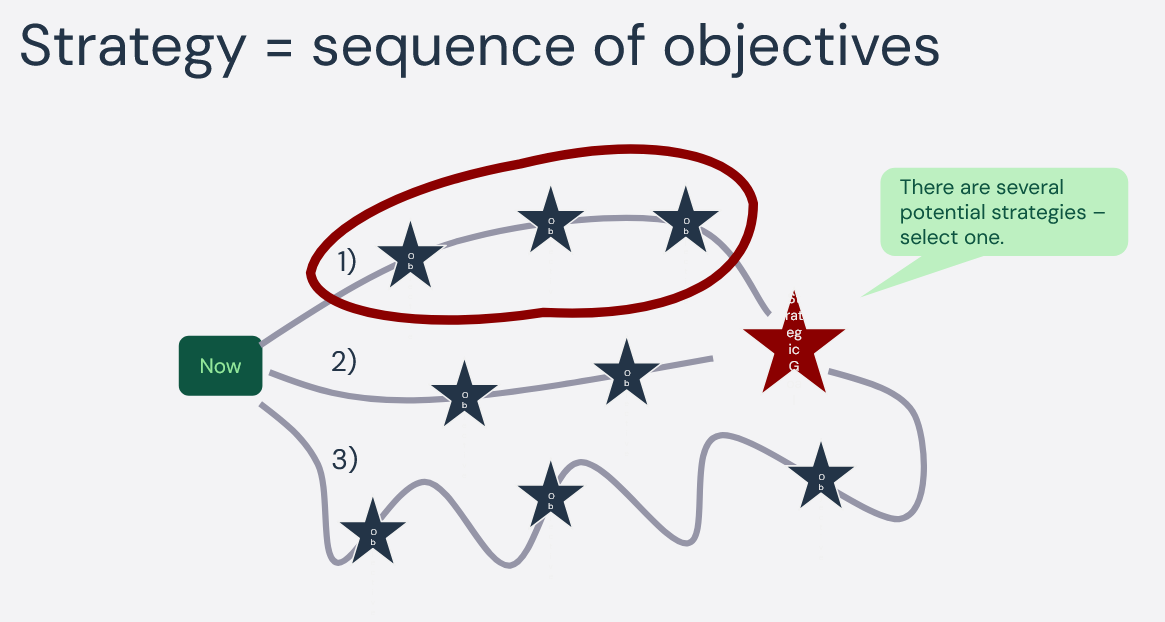
The old way – “slow feedback”
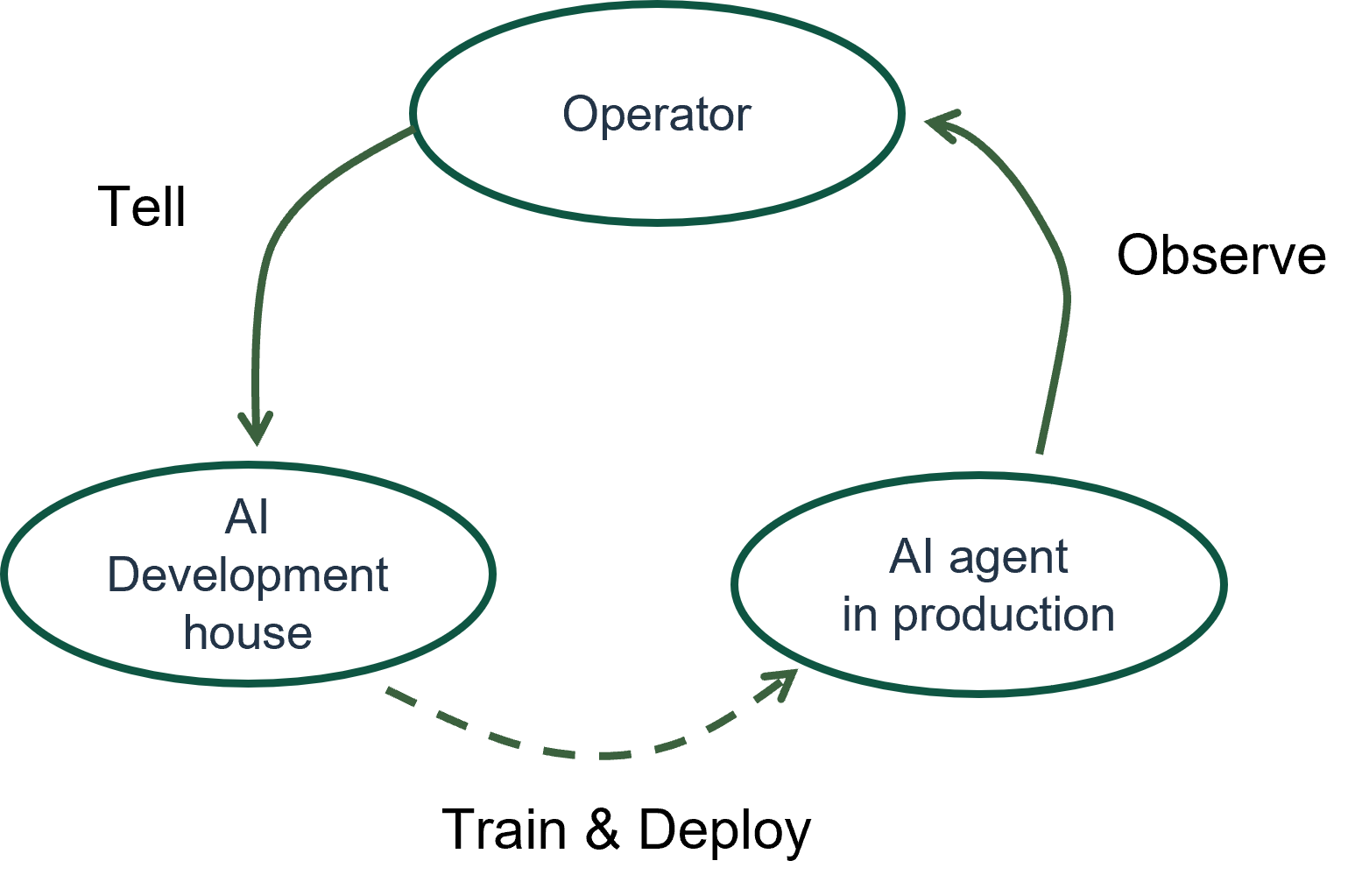
The new way – “fast feedback”
The AI strategy staircase
One of the most undervalued aspects of AI isn’t LLMs, it’s the stepping stones of simple yet robust techniques from Machine Learning that can deliver fast ROI with limited datasets.
If we categorize AI solutions by what they do, it would be:
- Categorize things. Examples: determine if an image contains a dog or a cat; if a painting is fake or real; detect cancer from X-ray; determine if a review in text contains a positive or negative sentiment.
- Predict things. Examples: What is the expected housing price during sale? As a smart watch with an accelerometer, what activity is my owner is up to? Other examples include: Tune input values for optimal outcome in production processes, chat bot answering questions, recommendations engines in online shopping.
- Real-time interaction with agents. For example, game play (Chess, Go), self-driving
The good news is that there is a simple solution to all of the above cases. Using simple techniques from Machine Learning, you can make predictions with fairly small data sets (200 data points). Compare this with using Deep Learning (neural networks) that drives LLMs, training those can require data sets with millions of data points. The flip side is that ML techniques saturate earlier (adding more data doesn’t improve accuracy).
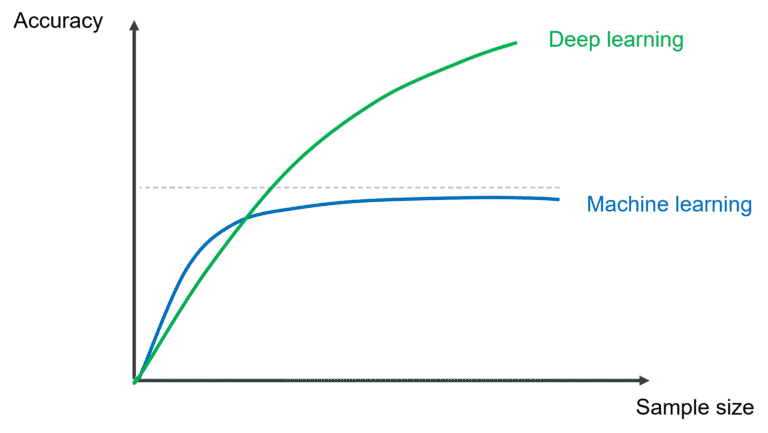
This brings us to the AI strategy staircase.
What most companies do wrong when implementing AI is that they start at the wrong end by implementing an LLM. This can produce a can of worms and unexpected dead ends.
Instead, do this: Start simple, and evolve when the value gain > risk. Let’s illustrate this:
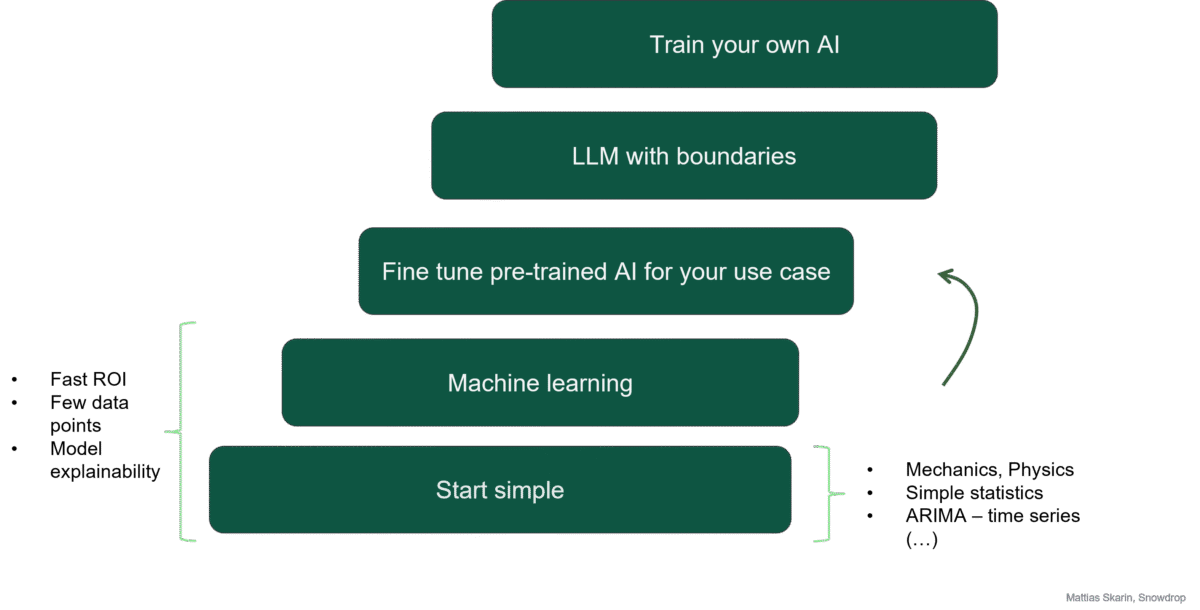
Step 1 – Start simple
We start simple. We begin by understanding the use case. The first thing to try is to solve the problem using simple algorithms, i.e. avoid throwing AI at the problem.
Starting simple brings another very important point into focus: If you transform a problem into an AI problem too early, you throw away solutions that are not technology related.
To give you an example, Volkswagen recently announced that they are investing €1B in using AI in product development to reduce lead time for new cars. Reducing lead time by 25% can easily be done with tried and tested practices without resorting to AI. In fact, I would venture to say that reducing lead time by as much as 50% is doable with far simpler means. It would make more sense to add AI only after you hit that wall.
I should add that I don’t have transparency to the Volkswagen project cited, very likely there is much more to it than meets the eye. I’m just using it to illustrate the general point that you shouldn’t start with turning problems that aren’t AI problems into such. Start simple :).
That said, in some cases, AI can the right approach to start with right off the bat. This is the case if the problem carries complex, non-linear relationships. In this scenario, programmable rules simply won’t cut it. The key point is that we might already know this for a fact when we start, so we start simple and evolve once we figured this out to be true.
Step 2 – Machine learning
Machine learning techniques have a set of benefits.
● ML allows us to make predictions on systems with complex, non-linear relationships.
● We can do this with a limited number of data points (a few hundred).
● We get fast ROI.
Step 3 – Fine tune pre-trained AIs for your use case
The next step up the ladder is to use a pre-trained AI (often a Deep Learning model) and then fine tune it with your own data. The good news here is that these AI solutions allow you to select between AI models with generative capability and those without.
You can find a growing library of pre-trained AIs on portals like Hugging Face.
Step 4 – LLMs with boundaries
The next step is applying an LLM with boundaries. A good starting point is to use an open source LLM and run it on-prem. This helps reduce data leakage issues.
If you go down this path it’s recommended to use LLM firewalls to screen for prompt injection and tighten up the API’s access to minimize security breaches, as LLMs with integrations allow for accessing APIs through natural language.
There are more tools than mentioned here that help keep an LLM within boundaries, for example, RAG (Retrieval-Augmented Generation) and AI agent frameworks.
Step 5 – Train your own AI
The final step is training your own AI. Given that this requires both large data sets and data science skills, this is not for everyone. What this will allow you to do is to produce differentiated, custom solutions in your specific business domain. This final step makes economic sense if your strategy is to scale or resell your solution.
Take on ethics and security challenges from the start
When building solutions based on AI, you have to realize that you are venturing in an area where there is no playbook. While cool new AI development tools pop up every month, the legal frameworks move at a slow pace. You simply cannot rely on the current legal frameworks when developing your AI system. You have to think through the ethics of it.
To give a grave example, Tesla is selling “full self-driving” as a feature to customers when the self-driving technology is really in the stage of development. You may argue that they didn’t break any law, but is it ethical? Is it the right thing to do? If we use the lens of ethics and consider the perspective of those who didn’t choose to opt in but got hurt, the answer is no.
What can you do then? The good news is that there are methodologies for evaluating the ethical aspects together with the development of your technology. In other words, you can do it in parallel. Look up “Value based engineering” and the standard ISO/IEC/IEEE 24748-7000.
Security is another example which you have to scrutinize in parallel with your AI solutions. AI solutions open up a whole new field of attack vectors for malicious actors such as Prompt injection and MCP hacks to name a few. Using natural language to access APIs opens up completely new possibilities for an attacker to read and write data they shouldn’t be able to.
My point is not to use the above reasons to stop learning about AI, but to take these perspectives seriously from the get go and develop ethics and security aspects in parallel with your AI solutions. Potential issues in these areas can be way hard, a lot harder than the technology itself if you have to “unfix” them after they have happened.
References
The Gen AI Divide: State of the AI in Business 2025, Fortune, 2025
Just How Bad Would an AI Bubble Be, The Atlantic, 2025